De Gruyter adopted the JATS/BITS schema for
journal content and established De Gruyter specific XML guidelines for creating XML
metadata and full text data. Together with le-tex, De Gruyter developed a submission
checker to validate the data quality of book and journal packages delivered from their
service vendors. The tool is based on the Open Source software Talend and transpect.
The submission checker verifies the consistency of metadata, validates against the
JATS schema and De Gruyter’s
business rules, which are specified with Schematron. An HTML report provides a rendering
of the source files with the error messages. The messages are displayed at the error
location and are grouped by their severity. Content passing the check is forwarded for
archiving and publication. It guarantees a technically correct rendering of the content on
degruyter.com and facilitates the retrieval and processing for future purposes.
Brief Description
Within this paper we'll describe De Gruyter’s JATS/BITS guidelines and its data checking
workflow. Furthermore, we discuss benefits and limitations of an automated data checking
utilizing Schematron and HTML reporting.
Introduction
De Gruyter has been an independent academic publisher of scientific content for over 260 years. About 1,200
book titles, more than 750 subscription based or Open Access journals, and a variety of digital products are
published every year. The content covers the subject areas humanities, social sciences, STM and law [1]. Besides its own brands and imprints, De Gruyter allocates the
e-publications of diverse Publisher Partners, like Harvard and Princeton University Press and integrates their
content into some of De Gruyters various product lines and business models.
To accomplish constantly high quality of content, fast publication times and at the same
time considering important characteristics of specific publishers or subject areas, De
Gruyter furthers standardization in many different areas. Therefore, within production
standardizing publication formats, streamlining processes as well as ensuring the compliance
of all aspects of it has become a major objective.
Background
Standards
The main focus to increase the efficiency was to have standards in place and raising the
number of journals and books using them. This was considered necessary to achieve better
conditions for production services and increase process stability and predictability. One
step to obtain more standardization was establishing the team eProducts and Standards
within the production department in 2013, which complements the books/journal production
department and the purchasing team. Since three years, the team is centrally responsible
for creating and maintaining new standards and guidelines. Also, the requirements for new
tools and software that serves the production process are described and implemented
accordingly.
Since then the numbers of standards increased rapidly. Until today around 30 documents,
that specify and classify product types, services they use and production processes, have
been created.
XML
To achieve a higher degree of automation and a greater flexibility for new content
models, XML guidelines became an important part within production. De Gruyter uses JATS and BITS schemas for archiving and
publishing their content. Within the De Gruyter XML Guidelines the specification for books
and journals are consolidated and unified to a large extent. At the same time
international standards such as ISO norms or Cross Ref standards are incorporated whenever
feasible. As a result De Gruyter can profit from tools, software and conversion services
that already implemented these standards.
Thus XML deliveries, their structure, naming and components need to be defined
explicitly. For De Gruyter this includes, apart from the XML itself, if available the
corresponding assets, such as figure and media files, a PDF equivalent and Electronic
Supplementary Material. All files are compiled within a ZIP package and conform to the
De Gruyter predefined naming convention and folder
structure. An issue delivery package will be built as follows:
Box 1
Structure and Naming Convention for an Issue Delivery
{journal-code-online}_{issue-id}_{timestamp}.zip
|--{issue-id}/
| |--{article-id}/
| | |--{article-id}.xml
| | |--{article-id}.pdf
| | |--graphic/
| | | |--{element-id}.jpg
| | | |-- (…)
| | |--media/
| | | |--{element-id}.m4a
| | | |--{element-id}.mp3
| | | |-- (…)
| | |--suppl/
| | | | |--{filename}.{fn-ext}
| |--{frontmatter-id}/
| | |--{frontmatter-id}.xml
| | |--{frontmatter-id}.pdf
| |--issue-files/
| | |--{issue-id}.xmlSince strict XML guidelines have not been available all along, backlist content has not been
created according to the latest guidelines. If these files need to be corrected and
re-uploaded for publication, De Gruyter defined more lax
guidelines to avoid high costs for adapting the content to the latest version of the De
Gruyter XML standards. They include the minimum requirements, which ensures a successful
processing and publication.
XML deliveries from Publisher Partners need to conform to De Gruyter guidelines as well. In some cases it is
inevitable to define exceptions for their content as not all specifications fit to the requirements of single
Publisher Partners.
Variables and IDs
Alongside XML tagging instructions, De Gruyter also defines standards for the structure
of variables and IDs. They are built using Regular Expressions or metadata information
from the ERP (Enterprise Resource Planning) system. Conventions for file or folder naming
are based on these definitions and part of the XML guidelines. For example,
element-ids (used within the attribute @id)
are build as follows:
Box 2
Building the Article ID
{article-id} = {doi-code}-{article-system-creation-date-year}-{article-counter-ID}
{doi-code} = [predefined value for each journal]
{article-system-creation-date-year} = ^\d{4}$
{article-counter-ID} = ^\d{4}$It illustrates the use of Regular Expressions and metadata information to form a new
variable, that could either be used by itself or in combination. Those IDs and variables
are primarily referenced by the XML guidelines, but are also used for others.
Motivation
The first issue has been the absence of XML guidelines. With establishing the team
eProducts and Standards a first version was developed and communicated. Over the years, the
XML instructions have been consolidated between books and journals to identify optimization
potential by unifying elements among different product types. At the same time typesetting
companies professionalized and were able to deliver XML files created from their production
process. These files were created according to the guidelines, delivered to the publisher
and put online. Errors within these deliveries became visible at different stages:
During the upload process to the media asset management system, when file naming
conventions weren't correct or meta data information was wrong.
While transforming the XML to HTML for De Gruyter Online, when XML files were not
well-formed, valid or meta data information was incorrect.
Through a visible check by the production editor (PE) at De Gruyter Online, when XML
elements have been used wrong or were missing.
If an error occurred, the PE had to get back to the vendor to correct the XML and instruct
him to re-upload the content (). In most cases,
this was a time consuming, inefficient process. Furthermore, some errors were not spotted as
the files were valid and the error didn't become visible with the HTML rendering. Despite
having valid and error-free XML files, it was not guaranteed that the XML delivered from
various vendors and created using different software was consistent and valid with regard to
all De Gruyter requirements.
As a manual and visual check of the XML deliveries from the production department was seen
as very inefficient and expensive, the obvious solution was to develop and implement an
automated checking tool to ensure the quality of the XML delivery.
Aim
The direct and narrow objective for a quality assurance tool was to have an automated check
for all XML deliveries regarding De Gruyter requirements that are specified within the
guidelines. The feedback in terms of errors should be returned to the vendor directly rather
than having production involved to forward or screen the report.
Indirect and broadly defined aims that can be seen as a result of the successful
implementation are:
Requirements
The basic requirements for the checking tool were to examine whether the delivered files
are valid and consistent XML files. That implies:
parse XML
validate XML
check consistency of identifiers (IDs such as journal-id, ISSNs, volume number ...)
match the internal list of files to referenced files
Processing Parameters
Another requirement was to have the Checking Tool as configurable as possible. Which
means, processing parameters should be integrated in a declarative manner so that De
Gruyter is capable of revising them independently from the general infrastructure and
programming code. These processing parameters include:
It should be possible to adjust these parameters without affecting the feasibility of the
tool.
Business Rules
Implementing the XML guidelines and specifications using Business Rules has been the
main requirement for the tool. To maintain the Rules internally as well, it was
explicitly defined to implement them using Schematron.
Cascading Rules
Book and journal publications are built upon the same rules for specific content (e.g. contributors,
abstract ...), but at the same time have a set of unique rules (e.g. different mandatory elements and
attributes). To avoid as much redundancies as possible a concept for cascading business rules was seen as
essential. In other words, starting from a general set of rules for all product types, a more specific
rule set for book or journal publications only is defined to overwrite or complement the global rules.
Strategically De Gruyter intends to add more cascading levels. Specific rules for different Publisher
Partners, imprints, business areas or even single book series or journals should be defined as part of the
cascades ().
It is expected that occasionally unforeseen content constellations appear within deliveries that may fail
the quality assurance tool. To have this content passing regardless, De Gruyter wants to define specific
journals as non-standard. These journals are supposed to be checked against a lax set of
business rules. This provides time to correct or implement additional rules or cascadings without having
to process the files manually.
Additionally it should be possible to distinguish between different types of
messages. There should be errors, whenever an element has not been created according
to the guidelines and the content cannot be declared as publishable. Warning messages
are supposed to be used as an information to the vendor that this will become an error
message soon, but for now can still be published.
Report
As a result of the checking process a file listing all errors and warnings should be
created and provided automatically to the vendor. Besides mentioning the error, the report
is expected to point to the tag, where the error or warning occurs. Depending on the
result of the report, the content is forwarded for publication or send back to the
vendor.
Implementation
After gathering and documenting all requirements, requests for proposals have been sent to
various vendors. Ultimately le-tex has been selected to implement the XML quality assurance
tool using their Open Source framework transpect (Transpect).
The following sections describe the implementation as well as all important and relevant
components. De Gruyter named the tool Submission Checker (SC) and it is referenced like that
subsequently within this paper.
Publication Workflow
Within the De Gruyter publication workflow the Submission Checker receives the
publication files from the vendor. After the checking process has been finished and no
errors have been found, the files are transferred and imported into the De Gruyter Media
Asset Management (MAM) system. Therefrom the content is forwarded to aggregators (like
Amazon, iBooks...) and published at De Gruyter Online. Additionally journal articles are
send to Abstracting and Indexing Services such as Scopus, Web of Science and PubMed. In
case the content delivery is incorrect, an error report is returned to the vendor to
correct and re-upload the files ().
FTP folder
To access the Submission Checker each vendor received an FTP login, where (s)he could
access the following folder structure:
Box 3
FTP folder structure
in/
error/
warning/
ok/
To trigger the Submission Checker, the vendor copies the content file (a ZIP package) to
the folder in. This folder is monitored and the file will be
forward for checking. Depending on the result of it, (s)he either receives an HTML report
within the folders error and warning or a
success message within the folder ok.
Talend
Talend is a data integration platform, that is used at De Gruyter to process and
transform files and information from various sources. Within the Submission Checker Talend
is part of several processes ():
Monitoring the "in" folders of each vendor on the FTP.
When a file is moved to the folder, Talend forwards it to transpect.
Talend interprets the product information extracted from transpect and delivers the
respective metadata information from the ERP system.
Talend analyzes the Status XML, that has been created during the checking process,
and processes the file according their status:
status=ok: the content will be send to the MAM system and a text file is
created within the respective ok folder containing the "ok" message.
status=warning: the content will be send to the MAM system and together with the
report html file it is also moved to the respective warning folder.
status=error: the content will not be send to the
MAM system, instead only
the report html file is moved to the respective error folder.
Transpect
Book and journal packages are validated with a customer-specific configuration of
transpect. Transpect is an Open Source framework for data conversion and checking and is
developed and maintained by le-tex, a Leipzig-based publishing service provider. The
framework not only involves various modules with specific features but also a methodology
to combine them into workflows.
While Talend manages the processing of files and metadata, transpect validates the
content files and performs important tasks within the Submission Checker framework:
Extract data and metadata from the zip package
Validate and check the XML documents.
Analyze the file structure and file naming conventions.
Check PDFs in the package and store their metadata.
Provide the final checking results to Talend.
The next section provides a brief overview of the technologies used by transpect.
Technologies
Transpect uses core XML technologies and standards. Here is a summary of the
technologies used for the Submission Checker and their purpose.
XProc is a
W3C standard to specify XML workflows. Transpect is based on various
XProc modules which provide specific features, such as unzip an archive, generate
HTML from JATS or validate XML with Schematron. A comprehensive list of all
transpect modules is provided by the transpect reference
[3]. The entire process logic of the Submission Checker
is laid out in XProc.
XSLT
2.0 is a programming language to transform XML-based data and a W3C
standard. Many Transpect modules rely on XSLT transformations. In the context of the
Submission Checker, XSLT is used for various conversion tasks such as processing XML
metadata, assembling Schematron files or transforming JATS to HTML.
Schematron is a rule-based validation language to declare
assertions for individual XML contexts. De Gruyter’s business rules such as XML
fulltext and metadata guidelines are implemented with Schematron.
RelaxNG is an XML schema language to specify patterns for the
structure of an XML document. All metadata and content files are specified in a
modular RelaxNG schema.
The next sections describe the key concepts of transpect in the context of De Gruyter’s Submission Checker
starting with the XML representation.
XML representation
It has often proved to be useful, to include all vital information in one document. For
example, a Schematron rule needs to compare if values in the XML match metadata values
or parts of the filename. Besides the XML-based content files, PDF properties, metadata,
file listings and parameters are stored as XML, too. Finally, the components are wrapped
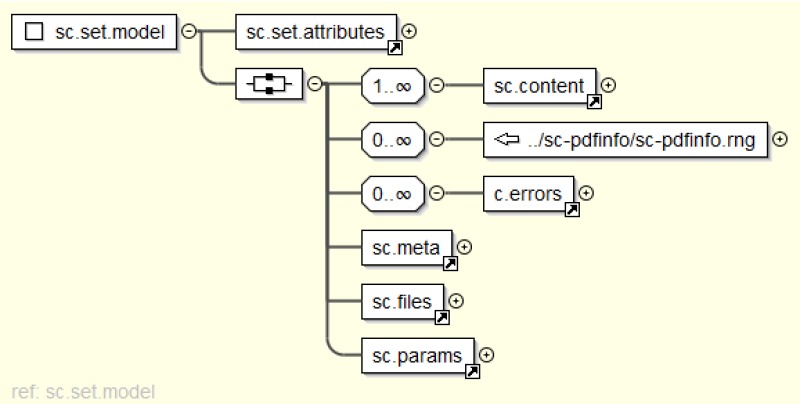
together in one XML set. The code sample below shows the basic XML structure.
Box 4
General structure of the XML set
<sc:set xmlns:sc="http://degruyter.com/xmlns/submissionchecker">
<sc:content>
<-- JATS journal article files or BITS book -->
</sc:content>
<sc:pdfinfo>
<-- PDF check results -->
</sc:pdfinfo>
<sc:meta>
<-- metadata from ERP system -->
</sc:meta>
<sc:files>
<-- Zip file listing -->
</sc:files>
<sc:params>
<-- Global Parameters -->
</sc:params>
</sc:set>The XML set schema consists of various components, each is described by an individual
RelaxNG schema. Therefore, the existing RelaxNG schemas for JATS and BITS where used and
custom schemas were specified for the other components.
Hence, the Submission Checker does not validate individual book or article files but
the entire XML representation of the package. In principle, this method is also useful
to bring other problems to light. For example, a failed PDF check or missing metadata
raise validation errors, too.
Cascades
The Submission Checker validates both book and journal packages. Although they follow
different XML schemas and XML guidelines, they are checked with the same architecture.
Because of similarities between JATS and BITS, some checks can be shared bewteen books
and journals.
Aside from general product differences, sometimes it seems to be necessary to exclude or soften some checks
for individual products. For example, De Gruyter produce XML packages in behalf of other publishers in the
context of De Gruyer’s Publisher Partner program. For some reasons, it is neither convenient nor necessary
for a publishing partner to comply with specific guidelines.
Therefore, transpect not only distinguishes between book and journal packages but also
allows to override specific rules based on a certain publisher, book, journal or even an
article. This is made possible by transpect’s configuration cascade: At
defined locations, configuration files in a hierarchic directory structure may reside.
Transpect analyzes the directory tree and the accompanied parameter files to get the
configuration cascade. After the configuration cascade is known, transpect derives the
matching cascades which applies to the current input file. Certain transpect modules
support the configuration cascade and are able to dynamically load their configuration
files, e.g. XSLT stylesheets, Schematron files, CSS files etc.
Box 5
Cascade directory structure
common/
|--params.xml
|--books/
| |--params.xml
|--journals/
| |--params.xml
In the context of the Submission Checker, transpect provides a general configuration,
which includes XProc pipelines, XSLT stylesheets and Schematron rules that are shared
among book and journal workflows. More specific Schematron rules and different RelaxNG
schemas are stored separately for books and journals. As shown in , it is planned to develop more detailed configuration levels up
to book series and journals.
Phases
Besides the configuration cascade, transpect also supports phases. The noun is adopted
from Schematron and describes custom checking profiles which correspond to a certain XML schema and a
Schematron phase. In addition to cascade levels, phases provide an additonal layer of configuration. A phase
can be statically passed as parameter or dynamically determined by analyzing the input file.
Currently, the Submission Checker includes two phases to provide different levels of
checking. A strict phase is intended for the daily production and a
lax phase for archive packages. In contrast to the
strict phase, the lax phase includes a smaller set
of Schematron patterns and allows more flavors of the JATS/BITS schema family.
The phase is evaluated by analyzing the input file against a set of product-related
rules. The rules are implemented in XSLT and stored separately for books and
journals.
Box 6
Configuration cascade for phases
common/
|--books/
| |--select-phase/
| | |--select-phase.xsl
|--journals/
| |--select-phase/
| | |--select-phase.xsl
For books and journal packages, the lax phase is selected, if the publication date of the book or article
is older than the release date of the Submission Checker. For journals only, the lax phase is indicated, if
a publisher or journal is tagged as non-standard in De Gruyter’s metadata. If the phase
evaluation fails, the strict phase is selected as fallback.
Global Parameter Sets
De Gruyter’s XML guidelines include various naming conventions, e.g. for file names,
identifiers and variables such as journal codes, chapter suffixes or counters. These
definitions frequently address other variables, as mentioned in Variables and IDs.
For this purpose, transpect uses parameter sets as part of the configuration cascade. A
parameter set is stored as XML in a specific cascade directory. The XML document
consists of parameter elements with key-value pairs. To indicate a reference to another
parameter, its name is wrapped in curly braces and tagged with a leading dollar
sign.
Box 7
Snippet of a parameter set
<?xml version="1.0" encoding="UTF-8"?>
<c:param-set xmlns:c="http://www.w3.org/ns/xproc-step">
<c:param name="article-id" value="{$doi-code}-{$article-system-creation-date-year}-{$article-counter-id}"/>
<c:param name="doi-code" value="[a-z]+"/>
<c:param name="date-year" value="\d{4}"/>
<c:param name="article-system-creation-date-year" value="{$date-year}"/>
<c:param name="article-delivery-type" value="(ja|aop)"/>
<c:param name="article-counter-id" value="\d{4}"/>
</c:param-set>The parameters are not only applied in Schematron checks but used throughout the entire
process chain. For example, when an issue file must be loaded, the global
issue-id parameter is used to find the correct file in the
package. Generally, the parameter sets provide a convenient way to set important
values which affect not only checks, but the entire process.
Schematron Implementation
Assembling Multiple Schematron Documents
According to the configuration cascade, different Schematron files are stored for
books, journals and both product types. Later, an XProc step [5] collects the Schematron files that apply to the current
package and compiles a global Schematron file. If a Schematron pattern exists twice in
multiple Schematron documents, the Schematron pattern from a more specific level
overrides more general Schematron patterns.
This method allows to define commonly used Schematron rules and overwrite them if
necessary on more specific cascade levels. In principle, it’s possible to override all
rules for a specific journal, although this wouldn't be very cost-efficient.
Use XSLT Functions in Schematron
The standard implementation of Schematron is based on XSLT: An XSLT generates another
stylesheet from the Schematron file which is applied to the XML file to be checked.
The output of the generated stylesheet is an SVRL report.
In contrast, transpect uses the oXygen’s Skeleton-based Schematron [4] implementation that allows foreign
elements. This method can be used to pass over XSLT code from Schematron to the
generated XSLT. This allows the definition of custom XSLT functions wich can be called
from XPath expressions. For example, the following Schematron snippet shows how a XSLT
function is used to check whether a proper ISO language code was used.
Box 8
Reference to an XSLT function in a Schematron assertion
<rule context="trans-abstract">
<assert test="if (@xml:lang)
then tr:is-valid-iso-lang-code(@xml:lang)
else false()" id="trans-abstract_attr">
The element <trans-abstract> must always contain the attibute @xml:lang with a language code according to ISO 639-1.
</assert>
</rule>
<xsl:function name="tr:is-valid-iso-lang-code" as="xs:boolean">
<xsl:param name="context" as="xs:string"/>
<xsl:value-of select="some $i in document('http://this.transpect.io/xslt-util/iso-lang/iso-lang.xsl')//tr:langs/tr:lang
satisfies $i/@code eq $context"/>
</xsl:function>Additional Markup
The author may use additional markup to add more semantic information to Schematron
messages. Equal to other approaches discussed at previous JATS-Cons [6][7], the role-attribute is used to
indicate the severity of a Schematron message.
Box 9
The role attribute indicates the severity of a Schematron rule.
<assert test="$subtitle-meta eq string-join(.//text(), '')" id="book-subtitle-match-metadata" role="error">
The value of book-title don't match the value found in our ERP system: '<value-of select="$subtitle-meta"/>'
</assert>
Additionally, HTML code can be used for authoring Schematron messages. This provides
more semantic markup which can later be rendered in the browser. Another use case is
to link the Schematron message to the corresponding rule in De Gruyter’s guidelines,
as shown in the example below.
Box 10
Schematron rule with HTML markup
<assert test="matches(., concat('^', $doi-prefixes, '/.+$'))" id="doi-prefix">
The DOI prefix '<value-of select="$doi-prefixes"/>' is expected for
publisher-name '<value-of select="$publisher-name"/>'. Please note that
this error can also be caused by an unknown publisher name or missing book-id.
<span xmlns="http://www.w3.org/1999/xhtml">
(See XML-Guidelines, section
'<a href="http://degruyter.com/foo/bar/guidelines.xhtml#publisher">Publisher</a>')
</span>
</assert>
HTML report
For users, the primary source of validation messages is the HTML report. The HTML
report shows the validation errors at the location where they occur.
The three column layout provides a navigation, the content with the error messages and a summary which
are grouped and can be filtered by their type:
- rule family
a group of related messages (i.e. Schematron file name, RelaxNG schema name)
- rule name
ID of the Schematron assert/report
- severity
role of the Schematron assert/report (e.g. warning, error, fatal-error)
The HTML report is generated in several steps. First, an intermediate HTML document is
generated from the XML representation of the package. The intermediate HTML document is
injected into the report template which provides the basic layout and includes
JavaScript and CSS resources. Finally, the RelaxNG and Schematron validation messages
are patched into the HTML report.
Workflow
Talend runs transpect two times. The first time, transpect is used to extract
identifiers such as book ISBN or article ID from the archive. Then Talend takes the
parameters and performs a request for the corresponding journal or book metadata from De
Gruyter’s ERP system. Afterwards Talend invokes transpect for a second time with the
metadata snippet for the current package. Finally transpect starts the actual validation
of the package.
The workflow comprises the following stages.
Unzip the archive and provide an XML listing of the files.
Check all PDFs and provide an XML representation of the checks.
Load metadata files from De Gruyter’s ERP system.
Evaluate the configuration cascade and the checking profile for the current
package.
Select the RelaxNG schema and assemble the Schematron rules which apply to the
configuration cascade and checking profile.
perform RelaxNG and Schematron validation
Convert JATS and BITS to HTML.
Inject the HTML in the report template and patch the RelaxNG and Schematron
validation messages in the context where the error occur.
Provide Talend with a summary of the checks as shown in the example below (Status
XML).
Box 11
The status XML provides a summary of the checks.
<c:param-set xmlns:c="http://www.w3.org/ns/xproc-step"
basename="aep_aep.2014.40.issue-3_2014-12-11--23-55-31" product="journal"
pub-type="issue" upload-date="2016-03-08+01:00" status="failed"
phase="strict" schema-valid="valid" type="report"
schematron-errors="33" schematron-warnings="0">
Benefits
In 2014 De Gruyter started using the Submission Checker for journal publications and
extended it in 2015 to process book files as well. Since then over 40.000 packages have been
processed. During this time of live implementation, various experiences have been made. Some
rules have been to strict to reflect the actual content, some had to be become stricter to
guarantee a successful rendering at De Gruyter Online or meet the requirements of related processes.
The effort within the production departments to manage error reports from different sources
has been minimized. There are remarkably less complaints about poor rendering of specific
content at degruyter.com.
Support regarding bugs or error messages that could not be interpreted by vendors are
managed by the eProducts and Standards team. That, on the one hand, allows the team to
constantly improve the Submission Checker itself, on the other hand returns valuable
feedback regarding the unambiguity of specifications and instructions within the XML
guidelines.
Despite having higher percentage of the delivered XML to conform to the De Gruyter guidelines,
the amount of error messages per month
decreased from around 30-40% to about 10-20% ().
This implies an improved XML process with the vendors.
The graphic also shows large deviations (e.g. August 2014, December 2015). They result from
major Submission Checker releases and the insufficient adaptions within the deliveries. That
again proves the necessity of automated quality assurance and the benefit for De Gruyter. It
would be out of De Gruyter’s scope to assure required
adjustments within the content otherwise.
A large benefit that evolves from an XML quality assurance tool lies more or less within
the future. De Gruyter is supposed to have advantages, when content or parts of it need to
be re-used for different or new types of publication, like a databases. In that case,
conversion efforts are expected to be relatively low since unpredictabilities have been
minimized within the checking process.
Outlook
As of now, the initial requirements have been implemented and additional features are
planned to realize within the next months. It is planned to realize the following
components:
IDPF epubcheck
For book publications, an EPUB file is required for each delivery. Therefore, a feature
is planned to check the EPUB file against the IDPF and the De Gruyter specific standards.
Fortunately, transpect already provides an module which implements the standard IDPF
epubcheck.
PDF check
Currently only the PDF metadata and the page count are evaluated. Additionally. it is
planned to check color and transparency settings, embedded fonts, crop marks and
bookmarks.
External Checking Framework for vendors
The experiences that have been made show, that having a checking process in place shortly
before publication is often inconvenient for vendors. Some errors only become visible at
this stage, which is too late since getting back and forth between correcting the file and
re-uploading it to the Submission Checker is very ineffective. At the one hand, De Gruyter
expects the vendor to have its own quality assurance in place that tests the content
continuously against the De Gruyter standards to prevent
errors at the stage of the SC. On the
other hand, within the Submission Checker schematron rules are used to verify the content
and it is anticipated, that extracting these rules and providing them to the vendor is
associated with relatively low effort. Besides it is expected, that error rates decrease
even more, which could result in lower support requests internally.
At the same time it needs to be considered that some checks rely on external files (see
Processing Parameters) which in some cases cannot be
delivered with the schematron rules (like metadata information from the ERP system). This makes it necessary
to omit these checks within this framework. Also testing the file structure and naming conventions of the
zip package should be excluded as it is can be assumed that single XML files are tested
during the production process rather than finalized ZIP files.
Conclusion
De Gruyter decided to archive their content in XML to leave divers options for re-use and
to optimize pre-publication processes. At the same time the XML files are prepared from
various vendors using different software and workflows. To make sure these files meet all
requirements having the Submission Checker in place to ensure their quality automatically is
inevitable.
Furthermore, De Gruyter is getting more familiar with the various structures within their
content. That on the one hand creates the opportunity to improve guidelines by unifying
elements or, if necessary, define specific rules and use configuration cascades. On the
other hand De Gruyter gains a better understanding of options and limits along with the JATS
schema family.
Finally, to opt for le-tex and its transpect framework was very beneficial as it complies
with De Gruyter's strategy to use industry standards whenever feasible. It was possible to
build on diverse modules and interfaces that are already implemented within Transpect. This
made it an efficient and advantageous project for both parties.
References
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
Blair J.
Developing a Schematron–Owning Your Content Markup: A Case Study. In: Journal Article Tag
Suite Conference (JATS-Con) Proceedings 2012 [Internet]. Bethesda (MD): National Center
for Biotechnology Information (US); 2012. [Accessed: 2016-03-11]
http://www.ncbi.nlm.nih.gov/books/NBK100373/- 7.
Usdin T, Lapeyre
DA, Glass CM. Superimposing Business Rules on JATS. In: Journal Article Tag Suite
Conference (JATS-Con) Proceedings 2015 [Internet]. Bethesda (MD): National Center for
Biotechnology Information (US); 2015. [Accessed: 2016-03-11]
http://www.ncbi.nlm.nih.gov/books/NBK279902/- 8.