By agreement with the publisher, this book is accessible by the search feature, but cannot be browsed.
Copyright © 2001, Garland Science.
Bookshelf ID: NBK27140

An official website of the United States government

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Janeway CA Jr, Travers P, Walport M, et al. Immunobiology: The Immune System in Health and Disease. 5th edition. New York: Garland Science; 2001.

Virtually any substance can elicit an antibody response. Furthermore, the response even to a simple antigen bearing a single antigenic determinant is diverse, comprising many different antibody molecules each with a unique affinity, or binding strength, for the antigen and a subtly different specificity. The total number of antibody specificities available to an individual is known as the antibody repertoire, or immunoglobulin repertoire, and in humans is at least 1011, perhaps many more. The number of antibody specificities present at any one time is, however, limited by the total number of B cells in an individual, as well as by each individual's encounters with antigens.
Before it was possible to examine the immunoglobulin genes directly, there were two main hypotheses for the origin of this diversity. The germline theory held that there is a separate gene for each different immunoglobulin chain and that the antibody repertoire is largely inherited. By contrast, somatic diversification theories proposed that the observed repertoire is generated from a limited number of inherited V-region sequences that undergo alteration within B cells during the individual's lifetime. Cloning of the immunoglobulin genes revealed that the antibody repertoire is, in fact, generated by DNA rearrangements during B-cell development. As we will see in this part of the chapter, a DNA sequence encoding a V region is assembled at each locus by selection from a relatively small group of inherited gene segments. Diversity is further enhanced by the process of somatic hypermutation in mature activated B cells. Thus the somatic diversification theory was essentially correct, although the concept of multiple germline genes embodied in the germline theory also proved true.
In nonlymphoid cells, the gene segments encoding the greater part of the V region of an immunoglobulin chain are some considerable distance away from the sequence encoding the C region. In mature B lymphocytes, however, the assembled V-region sequence lies much nearer the C region, as a consequence of gene rearrangement. Rearrangement within the immunoglobulin genes was originally discovered 25 years ago, when it first became possible to study the organization of the immunoglobulin genes in both B cells and nonlymphoid cells using restriction enzyme analysis and Southern blotting. In this procedure, chromosomal DNA is first cut with a restriction enzyme, and the DNA fragments containing particular V- and C-region sequences are identified by hybridization with radiolabeled DNA probes specific for the relevant DNA sequences. In germline DNA, from nonlymphoid cells, the V- and C-region sequences identified by the probes are on separate DNA fragments. However, in DNA from an antibody-producing B cell these V- and C-region sequences are on the same DNA fragment, showing that a rearrangement of the DNA has occurred. A typical experiment using human DNA is shown in Fig. 4.1.

Immunoglobulin genes are rearranged in B cells. The two photographs on the left (germline DNA) show a Southern blot of a restriction enzyme digest of DNA from nonlymphoid cells from a normal person. The locations of immunoglobulin DNA sequences are identified (more...)
This simple experiment showed that segments of genomic DNA within the immunoglobulin genes are rearranged in cells of the B-lymphocyte lineage, but not in other cells. This process of rearrangement is known as somatic recombination, to distinguish it from the meiotic recombination that takes place during the production of gametes.
The V region, or V domain, of an immunoglobulin heavy or light chain is encoded by more than one gene segment. For the light chain, the V domain is encoded by two separate DNA segments. The first segment encodes the first 95–101 amino acids of the light chain and is termed a V gene segment because it encodes most of the V domain. The second segment encodes the remainder of the V domain (up to 13 amino acids) and is termed a joining or J gene segment.
The rearrangements that lead to the production of a complete immunoglobulin light-chain gene are shown in Fig. 4.2 (center panel). The joining of a V and a J gene segment creates a continuous exon that encodes the whole of the light-chain V region. In the unrearranged DNA, the V gene segments are located relatively far away from the C region. The J gene segments are located close to the C region, however, and joining of a V segment to a J gene segment also brings the V gene close to a C-region sequence. The J gene segment of the rearranged V region is separated from a C-region sequence only by an intron. In the experiment shown in Fig. 4.1, the germline DNA fragment identified by the ‘V-region probe’ contains the V gene segment, and that identified by the ‘C-region probe’ actually contains both the J gene segment and the C-region sequence. To make a complete immunoglobulin light-chain messenger RNA, the V-region exon is joined to the C-region sequence by RNA splicing after transcription (see Fig. 4.2).

V-region genes are constructed from gene segments. Light-chain V-region genes are constructed from two segments (center panel). A variable (V) and a joining (J) gene segment in the genomic DNA are joined to form a complete light-chain V-region exon. Immunoglobulin (more...)
A heavy-chain V region is encoded in three gene segments. In addition to the V and J gene segments (denoted VH and JH to distinguish them from the light-chain VL and JL), there is a third gene segment called the diversity or DH gene segment, which lies between the VH and JH gene segments. The process of recombination that generates a complete heavy-chain V region is shown in Fig. 4.2 (right panel), and occurs in two separate stages. In the first, a DH gene segment is joined to a JH gene segment; then a VH gene segment rearranges to DJH to make a complete VH-region exon. As with the light-chain genes, RNA splicing joins the assembled V-region sequence to the neighboring C-region gene.
For simplicity, we have so far discussed the formation of a complete immunoglobulin V-region sequence as though there were only a single copy of each gene segment. In fact, there are multiple copies of all of the gene segments in germline DNA. It is the random selection of just one gene segment of each type to assemble a V region that makes possible the great diversity of V regions among immunoglobulins. The numbers of functional gene segments of each type in the human genome, as determined by gene cloning and sequencing, are shown in Fig. 4.3. Not all the gene segments discovered are functional, as a proportion have accumulated mutations that prevent them from encoding a functional protein. These are termed ‘pseudogenes.’ Because there are many V, D, and J gene segments in germline DNA, no single one is essential. This reduces the evolutionary pressure on each gene segment to remain intact, and has resulted in a relatively large number of pseudogenes. Since some of these pseudogenes can undergo rearrangement just like a normal functional gene segment, a significant proportion of rearrangements will incorporate a pseudogene and thus be nonfunctional.

The numbers of functional gene segments for the V regions of human heavy and light chains. These numbers are derived from exhaustive cloning and sequencing of DNA from one individual and exclude all pseudogenes (mutated and nonfunctional versions of a (more...)
The immunoglobulin gene segments are organized into three clusters or genetic loci—the κ, λ, and heavy-chain loci. These are on different chromosomes and each is organized slightly differently, as shown in Fig. 4.4 for humans. At the λ light-chain locus, located on chromosome 22, a cluster of Vλ gene segments is followed by four sets of Jλ gene segments each linked to a single Cλ gene. In the κ light-chain locus, on chromosome 2, the cluster of Vκ gene segments is followed by a cluster of Jκ gene segments, and then by a single Cκ gene. The organization of the heavy-chain locus, on chromosome 14, resembles that of the κ locus, with separate clusters of VH, DH, and JH gene segments and of CH genes. The heavy-chain locus differs in one important way: instead of a single C-region, it contains a series of C regions arrayed one after the other, each of which corresponds to a different isotype. Generally, a cell expresses only one at a time, beginning with IgM. The expression of other isotypes, such as IgG, can occur through isotype switching, as will be described in Section 4-16.
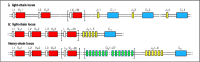
The germline organization of the immunoglobulin heavy- and light-chain loci in the human genome. The genetic locus for the λ light chain (chromosome 22) has about 30 functional Vλ gene segments and four pairs of functional Jλ gene (more...)
The human V gene segments can be grouped into families in which each member shares at least 80% DNA sequence identity with all others in the family. Both the heavy-chain and κ-chain V gene segments can be subdivided into seven such families, whereas there are eight families of Vλ gene segments. The families can be grouped into clans, made up of families that are more similar to each other than to families in other clans. Human VH gene segments fall into three such clans. All of the VH gene segments identified from amphibians, reptiles, and mammals also fall into the same three clans, suggesting that these clans existed in a common ancestor of these modern animal groups.
A system is required to ensure that DNA rearrangements take place at the correct locations relative to the V, D, or J gene segment coding regions. In addition, joins must be regulated such that a V gene segment joins to a D or J and not to another V. DNA rearrangements are in fact guided by conserved noncoding DNA sequences that are found adjacent to the points at which recombination takes place. These sequences consist of a conserved block of seven nucleotides—the heptamer 5′CACAGTG3′—which is always contiguous with the coding sequence, followed by a nonconserved region known as the spacer, which is either 12 or 23 nucleotides long. This is followed by a second conserved block of nine nucleotides—the nonamer 5′ACAAAAACC3′ (Fig. 4.5). The spacer varies in sequence but its conserved length corresponds to one or two turns of the DNA double helix. This brings the heptamer and nonamer sequences to the same side of the DNA helix, where they can be bound by the complex of proteins that catalyzes recombination. The heptamer-spacer-nonamer is called a recombination signal sequence (RSS).

Conserved heptamer and nonamer sequences flank the gene segments encoding the V regions of heavy (H) and light (λ and κ) chains. The spacer (white) between the heptamer (orange) and nonamer (purple) sequences is always either approximately (more...)
Recombination only occurs between gene segments located on the same chromosome. It generally follows the rule that only a gene segment flanked by a RSS with a 12-base pair (bp) spacer can be joined to one flanked by a 23 bp spacer RSS. This is known as the 12/23 rule. Thus, for the heavy chain, a DH gene segment can be joined to a JH gene segment and a VH gene segment to a DH gene segment, but VH gene segments cannot be joined to JH gene segments directly, as both VH and JH gene segments are flanked by 23 bp spacers and the DH gene segments have 12 bp spacers on both sides (see Fig. 4.5).
It is now apparent, however, that, even though it violates the 12/23 rule, direct joining of one D gene segment to another can occur in most species. In humans, D-D fusion is found in approximately 5% of antibodies and is the major mechanism accounting for the unusually long CDR3 loops found in some heavy chains. By creating extra-long CDR3s and unusual amino acid combinations, these D-D fusions add further to the diversity of the antibody repertoire.
The mechanism of DNA rearrangement is similar for the heavy- and light-chain loci, although only one joining event is needed to generate a light-chain gene whereas two are needed to generate a complete heavy-chain gene. The commonest mode of rearrangement (Fig. 4.6, left panels) involves the looping-out and deletion of the DNA between two gene segments. This occurs when the coding sequences of the two gene segments are in the same orientation in the DNA. A second mode of recombination can occur between two gene segments that have opposite transcriptional orientations. This mode of recombination is less common, although such rearrangements account for about half of all Vκ to Jκ joins; the transcriptional orientation of half of the human Vκ gene segments is opposite to that of the Jκ gene segments. The mechanism of recombination is essentially the same, but the DNA that lies between the two gene segments meets a different fate (Fig. 4.6, right panels). When the RSSs in such cases are brought together and recombination takes place, the intervening DNA is not lost from the chromosome but is retained in an inverted orientation.

V-region gene segments are joined by recombination. In every V-region recombination event, the signals flanking the gene segments are brought together to allow recombination to take place. For simplicity, the recombination of a light-chain gene is illustrated; (more...)
The molecular mechanism of V-region DNA rearrangement, or V(D)J recombination, is illustrated in Fig. 4.7. The 12 bp spaced and 23 bp spaced RSSs are brought together by interactions between proteins that specifically recognize the length of spacer and thus enforce the 12/23 rule for recombination. The DNA molecule is then broken in two places and rejoined in a different configuration. The ends of the heptamer sequences are joined precisely in a head-to-head fashion to form a signal joint in a circular piece of extrachromosomal DNA, which is lost from the genome when the cell divides. The V and J gene segments, which remain on the chromosome, join to form what is called the coding joint. This junction is imprecise, and consequently generates much additional variability in the V-region sequence.

Enzymatic steps in the rearrangement of immunoglobulin gene segments. Rearrangement begins with the binding of RAG-1, RAG-2, and high mobility group (HMG) proteins (not shown). These RAG-1:RAG-2 complexes (domes, colored green or purple for clarity although (more...)
The complex of enzymes that act in concert to effect somatic V(D)J recombination is termed the V(D)J recombinase. The products of the two genes RAG-1 and RAG-2 (recombination-activating genes) comprise the lymphoid-specific components of the recombinase. This pair of genes is only expressed in developing lymphocytes while they are engaged in assembling their antigen receptors, as is described in more detail in Chapter 7. They are essential for V(D)J recombination. Indeed, these genes, when expressed together, are sufficient to confer on nonlymphoid cells such as fibroblasts the capacity to rearrange exogenous segments of DNA that contain appropriate RSSs; this is how RAG-1 and RAG-2 were initially discovered.
Although the RAG proteins are required for V(D)J recombination, they are not the only enzymes in the recombinase. The remaining enzymes are ubiquitously expressed DNA-modifying proteins that are involved in double-stranded DNA repair, DNA bending, or the modification of the ends of the broken DNA strands. They include the enzyme DNA ligase IV, the enzyme DNA-dependent protein kinase (DNA-PK), and Ku, a well-known autoantigen, which is a heterodimer (Ku 70:Ku 80) that associates tightly with DNA-PK.
V(D)J recombination is a multistep enzymatic process in which the first reaction is an endonucleolytic cleavage requiring the coordinated activity of both RAG proteins. Initially, two RAG protein complexes, each containing RAG-1, RAG-2, and high-mobility group proteins, recognize and align the two RSSs that are guiding the join (see Fig. 4.7). RAG-1 is thought to specifically recognize the nonamer of the RSS. At this stage, the 12/23 rule is established through mechanisms that are still poorly understood. The endonuclease activity of the RAG protein complexes then makes two single-strand DNA breaks at sites just 5′ of each bound RSS, leaving a free 3′-OH group at the end of each coding segment. This 3′-OH group then hydrolyzes the phosphodiester bond on the other strand, sealing the end of the double-stranded DNA to create a DNA ‘hairpin’ out of the gene segment coding region. This process simultaneously creates a flush double-stranded break at the ends of the two heptamer signal sequences. The DNA ends do not float apart, however, but are held tightly in a complex by the RAG proteins and other associated DNA repair enzymes until the join is completed. The two RSSs are precisely joined to form the signal joint. Coding joint formation is more complex. First, the DNA hairpin is nicked open by a single-stranded break, again by the RAG proteins. The nicking can happen at various points along the hairpin, which leads to sequence variability in the eventual joint. The DNA repair enzymes in the complex then modify the opened hairpins by removing nucleotides (by exonuclease activity) and by randomly adding nucleotides (by terminal deoxynucleotidyl transferase, TdT). It is not known if addition and deletion of nucleotides at the ends of coding regions occurs simultaneously or in a defined order. Finally, ligases such as DNA ligase IV join the processed ends together to generate a continuous double-stranded DNA, thus reconstituting a chromosome that includes the rearranged gene. This enzymatic process seems to create diversity in the joint between gene segments, while ensuring that the RSS ends are ligated without modification, and that unintended genetic damage such as a chromosomal break is avoided.
The recombination mechanism controlled by the RAG proteins shares many interesting features with the mechanism by which retroviral integrases catalyze the insertion of retroviral DNA into the genome, and also with the transposition mechanism used by transposons (mobile genetic elements that encode their own transposase, allowing them to excise and reinsert themselves in the genome). Even the structure of the RAG genes themselves, which lie close together in the chromosome and lack the usual mammalian introns, is reminiscent of a transposon. Indeed, it has recently been shown that the RAG complex can act as a transposase in vitro. These features have provoked speculation that the RAG complex originated as a transposase whose function was adapted by vertebrates to allow V gene segment recombination, thus leading to the advent of the vertebrate adaptive immune system. Consistent with this idea, no genes homologous to the RAG genes have been found in nonvertebrates.
The in vivo roles of the enzymes involved in V(D)J recombination
have been established through natural or artificially induced mutations. Mice in
which either of the RAG genes is knocked out suffer a complete
block in lymphocyte development at the gene rearrangement stage. Mice lacking
TdT do not add extra nucleotides to the joints between gene segments. A mutation
that was discovered some time ago results in mice that make only trivial amounts
of immunoglobulins or T-cell receptors. Such mice suffer from a
severe combined immune deficiency—hence the name scid for this mutation. These mice have subsequently been found to have a
mutation in the enzyme DNA-PK that prevents the efficient rejoining of DNA at
gene segment junctions. Mutations of other proteins that are involved in DNA
joining also give the scid phenotype. ( Omenn Syndrome, in
Case Studies in Immunology, see Preface for details)
Omenn Syndrome, in
Case Studies in Immunology, see Preface for details)
Antibody diversity is generated in four main ways. Two of these are consequences of the recombination process just discussed (see Sections 4-4 and 4-5) which creates complete immunoglobulin V-region exons during early B-cell development. The third is due to the different possible combinations of a heavy and a light chain in the complete immunoglobulin molecule. The fourth is a mutational process that occurs in mature B cells, acting only on rearranged DNA encoding the V regions.
The gene rearrangement that combines two or three gene segments to form a complete V-region exon generates diversity in two ways. First, there are multiple different copies of each type of gene segment, and different combinations of gene segments can be used in different rearrangement events. This combinatorial diversity is responsible for a substantial part of the diversity of the heavy- and light-chain V regions. Second, junctional diversity is introduced at the joints between the different gene segments as a result of addition and subtraction of nucleotides by the recombination process. A third source of diversity is also combinatorial, arising from the many possible different combinations of heavy- and light-chain V regions that pair to form the antigen-binding site in the immunoglobulin molecule. The two means of generating combinatorial diversity alone could give rise, in theory, to approximately 3.5 × 106 different antibody molecules (see Section 4-7). Coupled with junctional diversity, it is estimated that as many as 1011 different receptors could make up the repertoire of receptors expressed by naive B cells. Finally, somatic hypermutation introduces point mutations into the rearranged V-region genes of activated B cells, creating further diversity that can be selected for enhanced binding to antigen. We will discuss these mechanisms at greater length in the following sections.
There are multiple copies of the V, D, and J gene segments, each of which is capable of contributing to an immunoglobulin V region. Many different V regions can therefore be made by selecting different combinations of these segments. For human κ light chains, there are approximately 40 functional Vκ gene segments and five Jκ gene segments, and thus potentially 200 different Vκ regions. For λ light chains there are approximately 30 functional Vλ gene segments and four Jλ gene segments, yielding 120 possible Vλ regions. So, in all, 320 different light chains can be made as a result of combining different light-chain gene segments. For the heavy chains of humans, there are 65 functional VH gene segments, approximately 27 DH gene segments, and 6 JH gene segments, and thus around 11,000 different possible VH regions (65 × 27 × 6 ≈ 11,000). During B-cell development, rearrangement at the heavy-chain gene locus to produce any one of the possible heavy chains is followed by several rounds of cell division before light-chain gene rearrangement takes place. The particular combination of gene segments used to produce a heavy chain does not appear to restrict the choice of gene segments that can be recombined to assemble a light-chain variable region. Thus, in theory any one possible heavy chain can be produced together with any one possible light chain in a single B cell. As both the heavy- and the light-chain V regions contribute to antibody specificity, each of the 320 different light chains could be combined with each of the approximately 11,000 heavy chains to give around 3.5 × 106 different antibody specificities. This theoretical estimate of combinatorial diversity is based on the number of germline V gene segments contributing to functional antibodies (see Fig. 4.3); the total number of V gene segments is larger, but the additional gene segments are pseudogenes and do not appear in expressed immunoglobulin molecules.
In practice, combinatorial diversity is likely to be less than one might expect from the theoretical calculations above. One reason for this is that not all V gene segments are used at the same frequency; some are common in antibodies, while others are found only rarely. It is also clear that not every heavy chain can pair with every light chain; certain combinations of VH and VL regions result in failure to assemble a stable immunoglobulin molecule. Cells that have heavy and light chains that cannot pair may continue to undergo light-chain gene rearrangement until a suitable light chain is produced, or may be eliminated, but in both cases a heavy- and light-chain combination that does not pair is lost from the repertoire. Nevertheless, it is thought that most heavy and light chains can pair with each other, and that this type of combinatorial diversity has a major role in the formation of an immunoglobulin repertoire with a wide range of specificities. In addition, two further processes add greatly to repertoire diversity—imprecise joining of V, D, and J gene segments and somatic hypermutation.
Of the three hypervariable loops in the protein chains of immunoglobulins, two are encoded within the V gene segment DNA. The third (HV3 or CDR3, see Fig. 3.6) falls at the joint between the V gene segment and the J gene segment, and in the heavy chain is partially encoded by the D gene segment. In both heavy and light chains, the diversity of CDR3 is significantly increased by the addition and deletion of nucleotides at two steps in the formation of the junctions between gene segments. The added nucleotides are known as P-nucleotides and N-nucleotides and their addition is illustrated in Fig. 4.8.

The introduction of P- and N-nucleotides at the joints between gene segments during immunoglobulin gene rearrangement. The process is illustrated for a DH to JH rearrangement; however, the same steps occur in VH to DH and in VL to JL rearrangements. After (more...)
P-nucleotides are so called because they make up palindromic sequences added to the ends of the gene segments. After the formation of the DNA hairpins as described in Section 4-5, the RAG protein complex catalyzes a single-stranded cleavage at a random point within the coding sequence but near the original point at which the hairpin was first formed. When this cleavage occurs at a different point from the initial break, a single-stranded tail is formed from a few nucleotides of the coding sequence plus the complementary nucleotides from the other DNA strand (see Fig. 4.8). In most light-chain gene rearrangements, DNA repair enzymes then fill in complementary nucleotides on the single-stranded tails which would leave short palindromic sequences at the joint, if the ends are rejoined without any further exonuclease activity (see below). In heavy-chain gene rearrangements and in some human light-chain genes, however, N-nucleotides are first added by a quite different mechanism.
N-nucleotides are so called because they are nontemplate-encoded. They are added by the enzyme terminal deoxynucleotidyl transferase (TdT) to single-stranded ends of the coding DNA after hairpin cleavage. After the addition of up to 20 nucleotides by this enzyme, the two single-stranded stretches at the ends of the gene segments form base pairs over a short region. Repair enzymes then trim off any nonmatching bases, synthesize complementary bases to fill in the remaining single-stranded DNA, and ligate it to the P-nucleotides (see Fig. 4.8). N-nucleotides are found especially in the V-D and D-J junctions of the assembled heavy-chain gene; they are less common in light-chain genes because TdT is expressed for only a short period in B-cell development, during the assembly of the heavy-chain gene, which occurs before that of the light-chain gene.
Nucleotides can also be deleted at gene segment junctions. This is accomplished by as yet unidentified exonucleases. Thus, the length of heavy-chain CDR3 can be even shorter than the smallest D segment. In some instances it is difficult, if not impossible, to recognize the D segment that contributed to CDR3 formation because of the excision of most of its nucleotides. Deletions may also erase the traces of P-nucleotide palindromes introduced at the time of hairpin opening. For this reason, many completed V(D)J joins do not show obvious evidence of P-nucleotides.
As the total number of nucleotides added by these processes is random, the added nucleotides often disrupt the reading frame of the coding sequence beyond the joint. Such frameshifts will lead to a nonfunctional protein, and DNA rearrangements leading to such disruptions are known as nonproductive rearrangements. As roughly two in every three rearrangements will be nonproductive, many B cells never succeed in producing functional immunoglobulin molecules, and junctional diversity is therefore achieved only at the expense of considerable wastage. We will discuss this further in Chapter 7.
The mechanisms for generating diversity described so far all take place during the rearrangement of gene segments in the initial development of B cells in the central lymphoid organs. There is an additional mechanism that generates diversity throughout the V region and that operates on B cells in peripheral lymphoid organs after functional immunoglobulin genes have been assembled. This process, known as somatic hypermutation, introduces point mutations into the V regions of the rearranged heavy- and light-chain genes at a very high rate, giving rise to mutant B-cell receptors on the surface of the B cells (Fig. 4.9). Some of the mutant immunoglobulin molecules bind antigen better than the original B-cell receptors, and B cells expressing them are preferentially selected to mature into antibody-secreting cells. This gives rise to a phenomenon called affinity maturation of the antibody population, which we will discuss in more detail in Chapters 9 and 10.

Somatic hypermutation introduces variation into the rearranged immunoglobulin variable region that is subject to negative and positive selection to yield improved antigen binding. In some circumstances it is possible to follow the process of somatic hypermutation (more...)
Somatic hypermutation occurs when B cells respond to antigen along with signals from activated T cells. The immunoglobulin C-region gene, and other genes expressed in the B cell, are not affected, whereas the rearranged VH and VL genes are mutated even if they are nonproductive rearrangements and are not expressed. The pattern of nucleotide base changes in nonproductive V-region genes illustrates the result of somatic hypermutation without selection for enhanced binding to antigen. The base changes are distributed throughout the V region, but not completely randomly: there are certain ‘hotspots’ of mutation that indicate a preference for characteristic short motifs of four to five nucleotides, and perhaps also certain ill-defined secondary structural features. The pattern of base changes in the V regions of expressed immunoglobulin genes is different. Mutations that alter amino acid sequences in the conserved framework regions will tend to disrupt basic antibody structure and are selected against. In contrast, the result of selection for enhanced binding to antigen is that base changes that alter amino acid sequences, and thus protein structure, tend to be clustered in the CDRs, whereas silent mutations that preserve amino acid sequence and do not alter protein structure are scattered throughout the V region.
The mechanism of somatic hypermutation is poorly defined, but there have been several new discoveries that shed some light. It is known that mutation requires the presence of enhancers, DNA sequences that enhance the trans-cription of immunoglobulin genes in B cells, as well as a transcriptional promoter. The promoter, and the sequences that are the target of mutation need not derive from immunoglobulin V genes, however. The generation of new mutations in V regions in mutating B cells has recently been shown to be accompanied by double-stranded breaks in the DNA which are thought to then be repaired in an error-prone way. In addition, it has recently been discovered that deficiency in an RNA editing enzyme called Activation Induced Cytidine Deaminase, blocks the accumulation of somatic hypermutations. The mechanism by which this enzyme contributes to hypermutation is unknown. Interestingly, deficiency of this enzyme also abrogates the rearrangement of C-region genes that underlies the immunoglobulin class switching seen in activated B cells (see Section 4-16).
As we have seen in the preceding sections, a proportion of the immunoglobulin diversity in an adult human derives from the existence of a variety of germline gene segments, and a proportion from somatic alterations acquired during the lifetime of the individual. This particular combination of heritable and acquired components of diversity operates in several mammalian immune systems, including those of humans and mice. Other species achieve a mix of inherited and acquired diversity by different means. Overall, it would appear that there is strong selective pressure to generate sufficient diversity in the immune system to protect the organism from common pathogens, and several different mechanisms have evolved toward this end.
In birds, rabbits, cows, pigs, sheep, and horses there is little or no germline diversity in the V, D, and J gene segments that are rearranged to form the genes for the initial B-cell receptors, and the rearranged V-region sequences are identical or similar in most immature B cells. These B cells then migrate to specialized microenvironments, the best known of which is the bursa of Fabricius in chickens. Here, B cells proliferate rapidly, and their rearranged immunoglobulin genes undergo further diversification. In birds and rabbits this occurs by a process that includes gene conversion, in which an upstream V segment pseudogene exchanges short sequences with the expressed rearranged V-region gene (Fig. 4.10). In sheep and cows, diversification is the result of somatic hypermutation, which occurs in an organ known as the ileal Peyer's patch. Somatic hypermutation probably also contributes to immunoglobulin diversification in birds and rabbits.

The diversification of chicken immunoglobulins occurs through gene conversion. In chickens, all B cells express the same surface immunoglobulin (slg) initially; there is only one active V, D, and J gene segment for the chicken heavy-chain gene and one (more...)
Diversity within the immunoglobulin repertoire is achieved by several means. Perhaps the most important factor that enables this extraordinary diversity is that V regions are encoded by separate gene segments, which are brought together by somatic recombination to make a complete V-region gene. Many different V-region gene segments are present in the genome of an individual, and thus provide a heritable source of diversity. Additional diversity, termed combinatorial diversity, results from the random recombination of separate V, D, and J gene segments to form a complete V-region exon. Variability at the joints between segments is increased by the insertion of random numbers of P- and N-nucleotides and by variable deletion of nucleotides at the ends of some coding sequences. The association of different light- and heavy-chain V regions to form the antigen-binding site of an immunoglobulin molecule contributes further diversity. Finally, after an immunoglobulin has been expressed, the coding sequences for its V regions are modified by somatic hypermutation upon stimulation of the B cell by antigen. The combination of all these sources of diversity generates a vast repertoire of antibody specificities from a relatively limited number of genes.
By agreement with the publisher, this book is accessible by the search feature, but cannot be browsed.
Your browsing activity is empty.
Activity recording is turned off.
See more...