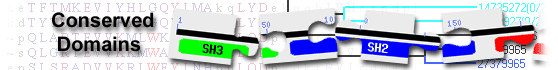


zinc finger protein 821 isoform X1 [Homo sapiens]
Protein Classification

C2H2-type zinc finger protein( domain architecture ID 10442881)
Cys2His2 (C2H2)-type zinc finger protein may be involved in transcriptional regulation
List of domain hits
| Name | Accession | Description | Interval | E-value | ||
| COG2433 super family | cl43687 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
260-334 | 5.57e-06 | ||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; The actual alignment was detected with superfamily member COG2433: Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 48.70 E-value: 5.57e-06
|
||||||
| zf-C2H2 | pfam00096 | Zinc finger, C2H2 type; The C2H2 zinc finger is the classical zinc finger domain. The two ... |
150-172 | 7.49e-03 | ||
Zinc finger, C2H2 type; The C2H2 zinc finger is the classical zinc finger domain. The two conserved cysteines and histidines co-ordinate a zinc ion. The following pattern describes the zinc finger. #-X-C-X(1-5)-C-X3-#-X5-#-X2-H-X(3-6)-[H/C] Where X can be any amino acid, and numbers in brackets indicate the number of residues. The positions marked # are those that are important for the stable fold of the zinc finger. The final position can be either his or cys. The C2H2 zinc finger is composed of two short beta strands followed by an alpha helix. The amino terminal part of the helix binds the major groove in DNA binding zinc fingers. The accepted consensus binding sequence for Sp1 is usually defined by the asymmetric hexanucleotide core GGGCGG but this sequence does not include, among others, the GAG (=CTC) repeat that constitutes a high-affinity site for Sp1 binding to the wt1 promoter. : Pssm-ID: 395048 [Multi-domain] Cd Length: 23 Bit Score: 33.81 E-value: 7.49e-03
|
||||||
| Name | Accession | Description | Interval | E-value | |||
| COG2433 | COG2433 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
260-334 | 5.57e-06 | |||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 48.70 E-value: 5.57e-06
|
|||||||
| CCDC47 | pfam07946 | PAT complex subunit CCDC47; This family represents CCDC47 proteins which are a component of ... |
293-354 | 1.51e-04 | |||
PAT complex subunit CCDC47; This family represents CCDC47 proteins which are a component of the PAT complex, an endoplasmic reticulum (ER)-resident membrane multiprotein complex that facilitates multi-pass membrane proteins insertion into membranes. The PAT complex, formed by CCDC47 and Asterix proteins, acts as an intramembrane chaperone by directly interacting with nascent transmembrane domains (TMDs), releasing its substrates upon correct folding, and is needed for optimal biogenesis of multi-pass membrane proteins. CCDC47 is required to maintain the stability of Asterix. CCDC47 is associated with various membrane-associated processes and is component of a ribosome-associated ER translocon complex involved in multi-pass membrane protein transport into the ER membrane and biogenesis. It is also involved in the regulation of calcium ion homeostasis in the ER, being also required for proper protein degradation via the ERAD (ER-associated degradation) pathway. Pssm-ID: 462322 Cd Length: 323 Bit Score: 43.33 E-value: 1.51e-04
|
|||||||
| U2AF_lg | TIGR01642 | U2 snRNP auxilliary factor, large subunit, splicing factor; These splicing factors consist of ... |
275-387 | 2.99e-04 | |||
U2 snRNP auxilliary factor, large subunit, splicing factor; These splicing factors consist of an N-terminal arginine-rich low complexity domain followed by three tandem RNA recognition motifs (pfam00076). The well-characterized members of this family are auxilliary components of the U2 small nuclear ribonuclearprotein splicing factor (U2AF). These proteins are closely related to the CC1-like subfamily of splicing factors (TIGR01622). Members of this subfamily are found in plants, metazoa and fungi. Pssm-ID: 273727 [Multi-domain] Cd Length: 509 Bit Score: 42.96 E-value: 2.99e-04
|
|||||||
| PTZ00121 | PTZ00121 | MAEBL; Provisional |
245-358 | 1.17e-03 | |||
MAEBL; Provisional Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 41.28 E-value: 1.17e-03
|
|||||||
| zf-C2H2 | pfam00096 | Zinc finger, C2H2 type; The C2H2 zinc finger is the classical zinc finger domain. The two ... |
150-172 | 7.49e-03 | |||
Zinc finger, C2H2 type; The C2H2 zinc finger is the classical zinc finger domain. The two conserved cysteines and histidines co-ordinate a zinc ion. The following pattern describes the zinc finger. #-X-C-X(1-5)-C-X3-#-X5-#-X2-H-X(3-6)-[H/C] Where X can be any amino acid, and numbers in brackets indicate the number of residues. The positions marked # are those that are important for the stable fold of the zinc finger. The final position can be either his or cys. The C2H2 zinc finger is composed of two short beta strands followed by an alpha helix. The amino terminal part of the helix binds the major groove in DNA binding zinc fingers. The accepted consensus binding sequence for Sp1 is usually defined by the asymmetric hexanucleotide core GGGCGG but this sequence does not include, among others, the GAG (=CTC) repeat that constitutes a high-affinity site for Sp1 binding to the wt1 promoter. Pssm-ID: 395048 [Multi-domain] Cd Length: 23 Bit Score: 33.81 E-value: 7.49e-03
|
|||||||
| Name | Accession | Description | Interval | E-value | |||
| COG2433 | COG2433 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
260-334 | 5.57e-06 | |||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 48.70 E-value: 5.57e-06
|
|||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
242-366 | 6.07e-05 | |||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 45.14 E-value: 6.07e-05
|
|||||||
| COG2433 | COG2433 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
259-364 | 8.35e-05 | |||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 44.85 E-value: 8.35e-05
|
|||||||
| CCDC47 | pfam07946 | PAT complex subunit CCDC47; This family represents CCDC47 proteins which are a component of ... |
293-354 | 1.51e-04 | |||
PAT complex subunit CCDC47; This family represents CCDC47 proteins which are a component of the PAT complex, an endoplasmic reticulum (ER)-resident membrane multiprotein complex that facilitates multi-pass membrane proteins insertion into membranes. The PAT complex, formed by CCDC47 and Asterix proteins, acts as an intramembrane chaperone by directly interacting with nascent transmembrane domains (TMDs), releasing its substrates upon correct folding, and is needed for optimal biogenesis of multi-pass membrane proteins. CCDC47 is required to maintain the stability of Asterix. CCDC47 is associated with various membrane-associated processes and is component of a ribosome-associated ER translocon complex involved in multi-pass membrane protein transport into the ER membrane and biogenesis. It is also involved in the regulation of calcium ion homeostasis in the ER, being also required for proper protein degradation via the ERAD (ER-associated degradation) pathway. Pssm-ID: 462322 Cd Length: 323 Bit Score: 43.33 E-value: 1.51e-04
|
|||||||
| U2AF_lg | TIGR01642 | U2 snRNP auxilliary factor, large subunit, splicing factor; These splicing factors consist of ... |
275-387 | 2.99e-04 | |||
U2 snRNP auxilliary factor, large subunit, splicing factor; These splicing factors consist of an N-terminal arginine-rich low complexity domain followed by three tandem RNA recognition motifs (pfam00076). The well-characterized members of this family are auxilliary components of the U2 small nuclear ribonuclearprotein splicing factor (U2AF). These proteins are closely related to the CC1-like subfamily of splicing factors (TIGR01622). Members of this subfamily are found in plants, metazoa and fungi. Pssm-ID: 273727 [Multi-domain] Cd Length: 509 Bit Score: 42.96 E-value: 2.99e-04
|
|||||||
| COG2433 | COG2433 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
249-370 | 3.08e-04 | |||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 42.92 E-value: 3.08e-04
|
|||||||
| DUF5401 | pfam17380 | Family of unknown function (DUF5401); This is a family of unknown function found in ... |
261-358 | 4.58e-04 | |||
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea. Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 42.42 E-value: 4.58e-04
|
|||||||
| PTZ00121 | PTZ00121 | MAEBL; Provisional |
245-358 | 1.17e-03 | |||
MAEBL; Provisional Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 41.28 E-value: 1.17e-03
|
|||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
260-366 | 2.92e-03 | |||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 39.92 E-value: 2.92e-03
|
|||||||
| PTZ00121 | PTZ00121 | MAEBL; Provisional |
262-358 | 3.39e-03 | |||
MAEBL; Provisional Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 39.74 E-value: 3.39e-03
|
|||||||
| PTZ00121 | PTZ00121 | MAEBL; Provisional |
249-358 | 4.78e-03 | |||
MAEBL; Provisional Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 39.35 E-value: 4.78e-03
|
|||||||
| PRK00247 | PRK00247 | putative inner membrane protein translocase component YidC; Validated |
256-341 | 5.52e-03 | |||
putative inner membrane protein translocase component YidC; Validated Pssm-ID: 178945 [Multi-domain] Cd Length: 429 Bit Score: 38.68 E-value: 5.52e-03
|
|||||||
| TPH | pfam13868 | Trichohyalin-plectin-homology domain; This family is a mixtrue of two different families of ... |
259-357 | 5.96e-03 | |||
Trichohyalin-plectin-homology domain; This family is a mixtrue of two different families of eukaryotic proteins. Trichoplein or mitostatin, was first defined as a meiosis-specific nuclear structural protein. It has since been linked with mitochondrial movement. It is associated with the mitochondrial outer membrane, and over-expression leads to reduction in mitochondrial motility whereas lack of it enhances mitochondrial movement. The activity appears to be mediated through binding the mitochondria to the actin intermediate filaments (IFs). The family is in the trichohyalin-plectin-homology domain. Pssm-ID: 464007 [Multi-domain] Cd Length: 341 Bit Score: 38.36 E-value: 5.96e-03
|
|||||||
| Nop53 | pfam07767 | Nop53 (60S ribosomal biogenesis); This nucleolar family of proteins are involved in 60S ... |
268-358 | 6.63e-03 | |||
Nop53 (60S ribosomal biogenesis); This nucleolar family of proteins are involved in 60S ribosomal biogenesis. They are specifically involved in the processing beyond the 27S stage of 25S rRNA maturation. This family contains sequences that bear similarity to the glioma tumour suppressor candidate region gene 2 protein (p60). This protein has been found to interact with herpes simplex type 1 regulatory proteins. Pssm-ID: 462259 [Multi-domain] Cd Length: 353 Bit Score: 38.43 E-value: 6.63e-03
|
|||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
270-383 | 6.81e-03 | |||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 38.76 E-value: 6.81e-03
|
|||||||
| zf-C2H2 | pfam00096 | Zinc finger, C2H2 type; The C2H2 zinc finger is the classical zinc finger domain. The two ... |
150-172 | 7.49e-03 | |||
Zinc finger, C2H2 type; The C2H2 zinc finger is the classical zinc finger domain. The two conserved cysteines and histidines co-ordinate a zinc ion. The following pattern describes the zinc finger. #-X-C-X(1-5)-C-X3-#-X5-#-X2-H-X(3-6)-[H/C] Where X can be any amino acid, and numbers in brackets indicate the number of residues. The positions marked # are those that are important for the stable fold of the zinc finger. The final position can be either his or cys. The C2H2 zinc finger is composed of two short beta strands followed by an alpha helix. The amino terminal part of the helix binds the major groove in DNA binding zinc fingers. The accepted consensus binding sequence for Sp1 is usually defined by the asymmetric hexanucleotide core GGGCGG but this sequence does not include, among others, the GAG (=CTC) repeat that constitutes a high-affinity site for Sp1 binding to the wt1 promoter. Pssm-ID: 395048 [Multi-domain] Cd Length: 23 Bit Score: 33.81 E-value: 7.49e-03
|
|||||||
| SF-CC1 | TIGR01622 | splicing factor, CC1-like family; This model represents a subfamily of RNA splicing factors ... |
284-358 | 8.17e-03 | |||
splicing factor, CC1-like family; This model represents a subfamily of RNA splicing factors including the Pad-1 protein (N. crassa), CAPER (M. musculus) and CC1.3 (H.sapiens). These proteins are characterized by an N-terminal arginine-rich, low complexity domain followed by three (or in the case of 4 H. sapiens paralogs, two) RNA recognition domains (rrm: pfam00706). These splicing factors are closely related to the U2AF splicing factor family (TIGR01642). A homologous gene from Plasmodium falciparum was identified in the course of the analysis of that genome at TIGR and was included in the seed. Pssm-ID: 273721 [Multi-domain] Cd Length: 494 Bit Score: 38.36 E-value: 8.17e-03
|
|||||||
| Blast search parameters | ||||
|
